
時間:2022-04-27 來源:原創 人氣:7563
1.基本概念
愛人的氣息是從不失職的溫柔路標,我們總能夠在一群人中一眼看到自己的愛人;同樣,愛人的聲音也總是那么獨特,在鼎沸的人聲中那么清晰。聽到TA的聲音后,其他一切聲音都已經被屏蔽了,一聲入耳,再無其他。
這就是人所謂的定向拾音的能力,當然這個比方不那么恰當。實際上這是經常聽說的“雞尾酒會效應”,指的是人能夠在復雜的升學環境中將注意力集中到某個人身上,并且忽略掉背景噪聲和其他人的聲音。這是人的聽覺選擇能力,涉及到雙耳結構以及復雜的大腦處理機制。
2.實現原理和方式
目前,利用麥克風模擬這種定向拾音能力,已經有了一定的成果。從實現方式上來看,可以分為單通道麥克風和多通道麥克風(麥克風陣列)兩種方式。
2.1 單通道麥克風
利用單通道麥克風實現定向拾音,指的是采用單指向性麥克風拾取單一方向聲音。麥克風的指向性指的是麥克風從指定方向拾取聲音,包括心型、超心型、全向星和8字型等拾音模式。
2.1.1 心型模式
拾音模式一個心型的圖案,通常被用在工作室錄制人聲中,是歌手較喜歡的麥克風。適用于不想拾取觀眾的聲音或者從監控器中傳出的聲音。在工作室中,使用心型麥克風可以有效的降低環繞聲和麥克風反射回來的聲音。拾音模式如圖1所示。理論上說,這種心型模式的拾音前后比可達到20dB以上,實際測試結果顯示,常見的信心模式麥克風能達到10dB已經是很好的表現了。
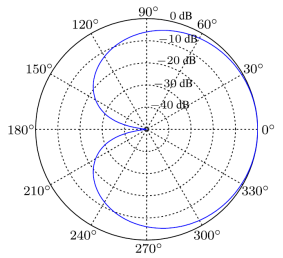
圖1 心型拾音模式
這種指向性的麥克風的拾音模式如圖2所示,在舞臺上它們能夠更好的收錄主唱的聲音,并且阻擋周圍樂隊的聲音,其缺點是也會收錄一些麥克風后面的聲音。這就意味不應該將你的監聽音箱放在面前(一般情況下120或者240度的位置較好)。超心型話筒的指向性比心型更窄,特別適合近距離拾音。

圖2 超心型模式
2.1.3 全向型模式
這就是常見的無指向性麥克風,對所有角度都有相同的靈敏度,這意味著它可以從所有方向均衡地拾取聲音。這種麥克風完全沒有指向性,不能用于定向拾音的場合。

圖3 全向型模式
2.1.4 8字型模式
顧名思義,8字型麥克風的拾音形狀類似數字8,也叫雙心型麥克風或也被叫做是雙指向形,它們通常被用在工作室而不是現場,而且大部分此類麥克風都是鋁帶式麥克風。它們從前方和后發拾取聲音,而不是從兩側。這種是在正面和背面較靈敏左右測不夠靈敏,因為這種指向類型的話筒對來自話筒正前方和正后方的音頻信號具有同樣高的靈敏度,但是對來自話筒側面的信號不太敏感。
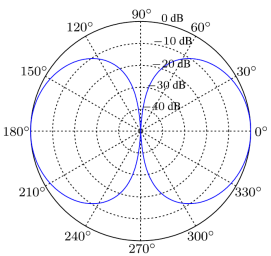
圖4 8字型拾音模式
采用單通道麥克風實現定向拾音,可以實現一定程度上的定向效果,但對其他方向上的干擾抑制能力是遠遠不夠的。我們只想聽到TA的聲音,但這種單指向性的麥克風做不到這一點,第三者、第四者乃至更多的聲音都會不可避免地泄漏進來。因此,需要采用更好的設計方案,即多通道麥克風(麥克風陣列)方案,實現更好的定向拾音效果。
2.2 麥克風陣列方案
麥克風陣列是由按照特定的拓撲結構分布在空間的多個麥克風組合而成。與單個麥克風相同,麥克風陣列為一個整體,仍然可以看作一個復雜的傳感器,作為聲音與拾音系統的接口模塊;但不同的是,麥克風陣列不但可以獲得聲音信號的時域信息還可以獲得空域信息。麥克風陣列信號處理的主要目標是盡可能地利用空時信息來提高接收端信號的質量。
在使用麥克風陣列對語音信號進行處理的發展歷程中,產生了許多陣列結構,包括結構相對簡單的直線陣列、平面陣列以及復雜的三維球陣列。圖5給出了N個麥克風等間距直線陣列的模型,θ為聲源的方位角。
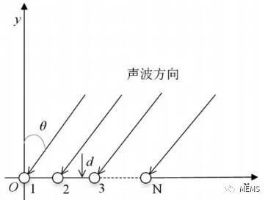
圖5 直線陣列模型
在定向拾音中,直線陣列是較常見的結構。對應兩種拾音模式:端射和寬邊模式。簡單地說,端射模式的拾取方向是陣列軸線方向,而寬邊模式拾取的方式是與陣列軸線垂直的方向。
2.2.1 端射模式
較常見的端射模式實現方式為微分麥克風陣列,有時候也稱為差分麥克風陣列。差分陣列表現的是空間聲壓的差異性,聲壓的一階差分可以由兩個相近放置的全向麥克風輸出相減得到,同理,N個麥克風可以獲得聲壓的N-1階差分。
下面以圖6所示的兩麥克風組成的差分陣列為例,介紹差分陣列的定向拾音模式的設計思路。兩麥克風組成的差分陣列,對應的是階次為1,有兩個設計約束條件:
1.在目標方向無失真(θ=0°時,拾音增益為1);
2.在0°<θ≤180°的范圍內存在一個零陷。
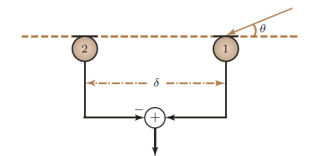
圖6 一階差分陣列
令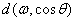 表示麥克風陣列的導向矢量,以圖6所示的陣列為例,導向矢量為
表示麥克風陣列的導向矢量,以圖6所示的陣列為例,導向矢量為

設計目標就是為兩個麥克風選擇合適的權重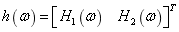 ,滿足上面的兩個約束條件,即
,滿足上面的兩個約束條件,即

以心型模式為例,可求解得到權重h(ω):

對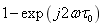 取泰勒近似,可將上式近似改寫為
取泰勒近似,可將上式近似改寫為
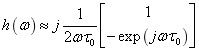
 并與麥克風1的信號相減之后,再進行一個低通濾波的結果。顯然,差分麥克風陣列體現的是一種“延遲相減”的思路,將不希望拾取的信號通過相減的方式抵消掉。
并與麥克風1的信號相減之后,再進行一個低通濾波的結果。顯然,差分麥克風陣列體現的是一種“延遲相減”的思路,將不希望拾取的信號通過相減的方式抵消掉。GSC方法由兩條支路組成,如圖7所示,上面的支路固定波束形成器(Fixed Beamformer,FBF)支路,一般由DSB算法實現,用以增強目標方向信號,抑制其他方向的干擾;下面一條支路由阻塞矩陣(Blocking Matrix,BM)和自適應干擾抵消器(Adaptive Interference Canceler,AIC)兩部分組成,阻塞矩陣用以獲得目標信號零陷位置的參考噪音信號,該信號與DSB輸出中的噪音信號相關,自適應干擾抵消器利用該參考噪音信號估計DSB輸出中的噪音信號,并從DSB輸出信號中減去該估計信號,得到波束形成輸出信號。
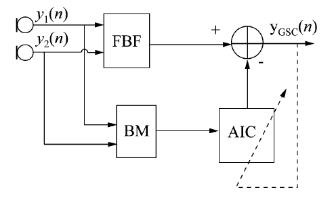
圖7 GSC算法結構
在二元麥克風小陣列中,由于兩個陣元間距較小,它們的脈沖響應函數可以近似的認為是相等的或者其差別可以忽略不計。由圖6可知,第二個麥克風相對于第一個麥克風的目標信號相位差為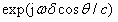 ,DSB方法就是對兩路麥克風信號進行時間上的對齊(即頻域的相位補償),對應DSB輸出為:
,DSB方法就是對兩路麥克風信號進行時間上的對齊(即頻域的相位補償),對應DSB輸出為:
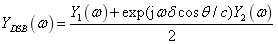
阻塞矩陣BM按照如下方式定義:
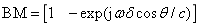
計算語音存在先驗概率:

其中,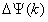 表示頻點k所對應的相位差,即
表示頻點k所對應的相位差,即
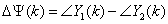
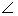 表示取相位。需要注意的,相位差
表示取相位。需要注意的,相位差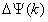 需要解卷繞到(-π,π]的區間中。
需要解卷繞到(-π,π]的區間中。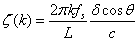 表示相位差閾值,fs表示采樣頻率(Hz)。
表示相位差閾值,fs表示采樣頻率(Hz)。考慮到相鄰頻點之間存在高度的相關性,因此,可以對相鄰頻點的語音存在概率進行平滑,提高頻率計算結果的準確性和相鄰幀之間結果的連續性。平滑后的各頻點語音存在先驗概率如下所示:
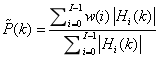
其中,w(i),i=0,1,...,I-1表示Gammatone濾波器系數,I為Gammatone通道的數量,典型值為I=20或40等,根據具體需求而定。按照下式進行計算:
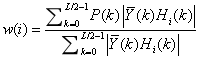
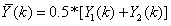 表示兩路通道的信號均值。Hi(k),i=0,1,...,I-1表示Gammatone濾波器曲線的采樣值。
表示兩路通道的信號均值。Hi(k),i=0,1,...,I-1表示Gammatone濾波器曲線的采樣值。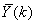 作為單通道語音信號,按照常見的噪聲譜估計方法,如最小值追蹤方法等,計算
作為單通道語音信號,按照常見的噪聲譜估計方法,如最小值追蹤方法等,計算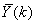 對應的噪聲功率譜,用λ(k)表示。
對應的噪聲功率譜,用λ(k)表示。計算后驗信噪比:

求語音存在的先驗概率的均值,以此作為判斷單幀信號是否存在語音的一個標識:
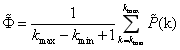
求語音不存在后驗概率q(k):

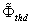 表示先驗概率均值的閾值,與拾音范圍角度的大小有關系,當確定了拾音范圍角度之后,方可確定這個閾值。
表示先驗概率均值的閾值,與拾音范圍角度的大小有關系,當確定了拾音范圍角度之后,方可確定這個閾值。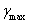 表示后驗信噪比的最大值,取4~5之間的值,可取得較好的調試結果。
表示后驗信噪比的最大值,取4~5之間的值,可取得較好的調試結果。計算處理后的語音:

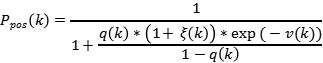
3.應用
定向拾音技術的應用比較廣泛,較常見的應用場合是本地擴聲。在本地擴聲中,由于定向拾音技術可以壓制某個方向上的聲音,因此可以將播音設備放置在這個方向,能夠很大程度上抑制可能發生的嘯叫,從而解決困擾本地擴聲的較大問題之一,在教室、會場等擴聲場景中都有很大的應用潛力。此外,該技術在存在角色分離錄音要求的場合也都有潛在的應用空間。

掃一掃加好友咨詢